프로메테우스 모니터링의 범주와 흐름
2024. 8. 20. 21:03ㆍKubernetes
본 내용은 책 '프로메테우스 오픈소스 모니터링 시스템' 의 1장 내용을 정리한 것입니다.
모니터링의 범주
| 범주 | 개념 | 예시 |
| 프로파일링 (Profiling) |
모든 시간대의 모든 이벤트의 컨텍스트를 가질수는 없지만, 제한된 기간의 일부 컨텍스트를 가질 수 있다는 방식 |
|

출처: https://www.brendangregg.com/blog/2019-01-01/learn-ebpf-tracing.html
| 범주 | 개념 | 예시 |
| 트레이싱 (Tracing) |
|
X |
| 분산 트레이싱 | 트레이싱에서 한단계 더 나아가, 원격 프로시저 호출에서 한 프로세스에서 다른 프로세스로 전달되는 요청에 고유한 ID를 추가해서 해당 요청이 추적되어야 하는지 여부 등 프로세스 전반에 걸친 작업을 추적한다. |
|

출처: https://www.jaegertracing.io/docs/1.17/
| 범주 | 개념 | 예시 |
| 로깅 (Logging) |
제한된 이벤트 집합을 살펴보고 각 이벤트에 대한 컨텍스트 일부를 기록한다. |
|
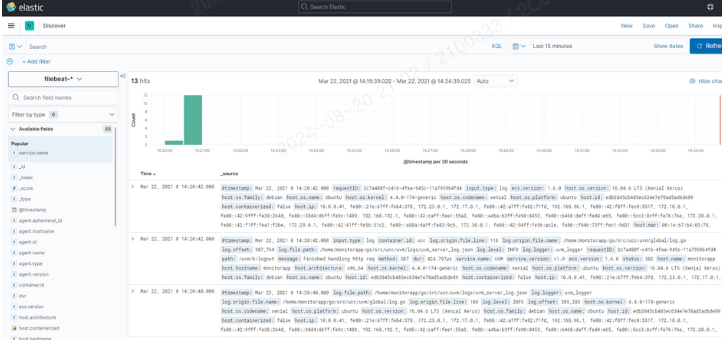
출처: https://www.gimsesu.me/manage-logs-with-elastic-stack-2/
| 범주 | 개념 | 예시 |
| 메트릭 | 컨텍스트를 대부분 무시하고 다양한 유형의 이벤트에 대해 시간에 따른 집계를 추적한다. Tip! 자원사용을 정상적으로 유지하려면, 추적하는 메트릭 개수를 제한해야한다. 프로세스당 1만개의 메트릭 처리정도가 합리적인 상한선이다. |
|
프로메테우스 아키텍쳐
프로메테우스의 흐름
1. 익스포터를 통해 계측 애플리케이션이나 서드파티 애플리케이션 등에서 데이터를 수집한다.
2. 수집된 데이터가 저장되면, PromQL 을 이용해 대시보드에서 활용되거나, 알람매니저를 통해 알림이 발송된다.
3. 알림은 무선호출, 이메일 같은 통보로 발현된다.
| 과정 | 개념 | 예시 |
| 클라이언트 라이브러리 |
|
CPU 사용량, 가비지컬렌션의 통계치 등 (주요 언어와 런타임에서 사용가능 ) https://prometheus.io/docs/instrumenting/clientlibs/ |
| 익스포터 |
|
사용자 정의 수집기(Custom collectors), ConstMetrics 등 |
| 서비스 검색 |
|
|
| 데이터 수집 |
|
|
| 저장 장치 |
|
|
| 대시보드 |
|
|
| 기록 규칙 및 알림 |
|
|
| 알림 매니저 |
|
|
| 장기저장소 |
|
프로메테우스가 적합한 경우와 아닌 경우
적합한 경우
- 커널 스케줄링, 데이터 수집 실패같은 요소 보완하는 데 좋다.
부적합한 경우
- 이벤트 로그나 개별 이벤트를 저장하는데는 적합하지 않다.
- 이메일 주소나 사용자 이름같이 카디널리티가 높은 데이터에도 최상의 선택은 아니다.
'Kubernetes' 카테고리의 다른 글
| Cloud Native Korea Community Day 2024 다녀와서.. (0) | 2024.09.29 |
|---|---|
| Dockerfile 어떻게 동작하지 하다가 Docker 정리글을 쓰게됐다. (0) | 2024.08.06 |
| openshift pod 에 umask 설정하는법 (0) | 2024.03.26 |
| 쿠버네티스 인 액션 10장 ( Statefulset ) (0) | 2023.09.09 |
| 쿠버네티스인 액션 6장 볼륨 (0) | 2023.08.19 |